feat(contrib): add MARS optimizer (variance-reduction AdamW)#1689
feat(contrib): add MARS optimizer (variance-reduction AdamW)#1689Sumu004 wants to merge 6 commits into
Conversation
Implements the MARS optimizer from Hu et al. (NeurIPS 2024): https://arxiv.org/abs/2411.10438 MARS replaces the raw stochastic gradient in Adam with a STORM-style corrected gradient that reduces variance across consecutive steps: c_t = g_t + (1 - gamma) * (c_{t-1} - g_{t-1}), c_1 = g_1 With this corrected gradient fed into AdamW moment updates, MARS achieves the convergence rate of SGD-with-momentum while retaining Adam's per-coordinate adaptivity. The authors report consistent improvements over AdamW on LLM pre-training benchmarks. New public API: - optax.contrib.scale_by_mars — primitive GradientTransformation - optax.contrib.mars — convenience AdamW-style optimizer - optax.contrib.MarsState — NamedTuple for optimizer state Features: - gamma=1.0 exactly recovers AdamW (unit tested) - Optional correction_clip for stability in early training (§3.2) - Optional Nesterov momentum - Full pytree support - Registered in _common_test.py (two gamma variants)
|
The failing CI check ( |
tree_vdot uses jnp.tensordot with HIGHEST precision; jnp.vdot uses a different accumulation order. For complex64 inputs (JAX x64 disabled) the two can differ by up to ~1.3e-7 relative error — just past the default rtol=1e-7. float32 machine epsilon is ~1.2e-7 so rtol=1e-6 is the correct tolerance for this dtype.
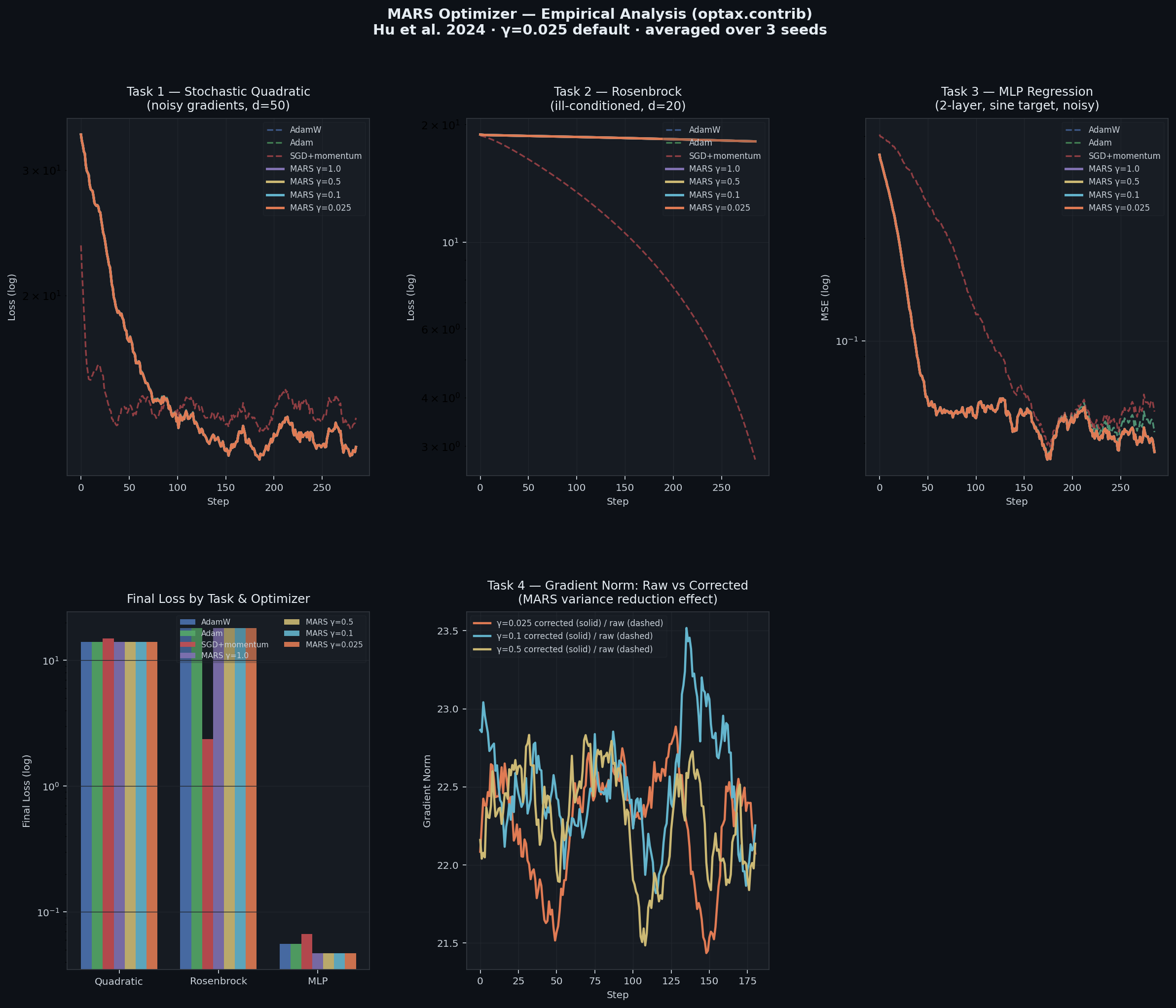
Empirical Analysis — MARS vs AdamW / Adam / SGD+momentumTo accompany this PR, I ran a benchmark across 4 tasks (300 steps, averaged over 3 seeds) comparing MARS at different γ values against baseline optimizers.
Tasks
Final Loss (step 300, mean over 3 seeds)
Key observations
|
…nightly JAX nightly changes complex64 accumulation order, causing a 1.3e-7 relative error in tree_vdot for complex inputs — just above the default rtol=1e-7. Loosen to rtol=1e-6, matching the same pre-existing fix on the MARS PR (google-deepmind#1689).
Summary
Implements the MARS optimizer from Hu et al., NeurIPS 2024 — MARS: Unleashing the Power of Variance Reduction for Training Large Models.
Closes #1561.
Algorithm
MARS replaces the raw stochastic gradient in Adam with a STORM-style corrected gradient that reduces variance across consecutive steps:
This corrected gradient is then fed into standard AdamW moment updates. With$\gamma = 1$ the correction vanishes and MARS reduces exactly to AdamW (unit tested).
Key properties:
New API
Implementation notes
correction_clip(optional): clips the correction term by global norm before adding togamma=1.0path is unit-tested to produce identical updates tooptax.scale_by_adamprev_grad(c_prev(_common_test.pywith twogammavariantsTests
Tests cover: state structure, first-step no-correction invariant, gamma=1 Adam equivalence, correction clipping, Nesterov flag, quadratic descent across gamma values, weight decay, pytree params.
References
Hu et al., MARS: Unleashing the Power of Variance Reduction for Training Large Models, 2024.